Originally published at: AI Video Research: What’s new in 2023
This post will summarize the current state of Artificial Intelligence (AI) applications for video in 2023, including recent progress and announcements. We’ll also take a closer look at AI video research and collaboration between Bitmovin and the ATHENA laboratory that has the potential to deliver huge leaps in quality improvements and bring an end to playback stalls and buffering. Keep reading to learn more!
- AI for video in 2023
- Bitmovin and ATHENA AI Research
- Better quality with neural network-driven Super Resolution upscaling
- Less buffering and higher QoE with applied machine learning
- Challenges ahead
- Learn more
- AI Video Glossary
AI for video in 2023
2022 was the year text-to-image generative AI went mainstream as models like Midjourney, Stable Diffusion and DALL-E 2 opened new, seemingly magical possibilities for image creation. They exploded in popularity as everyone from designers to meme makers explored their capabilities. In 2023, the wave of interest kept growing and expanded into video generation models, ultimately culminating in the instant internet classic, Will Smith eating spaghetti.

As fun and exciting (or maybe terrifying) as that is, generative AI is just one of the emerging use cases for video. Nvidia released an AI-powered software called Eye Contact that can make it look like you’re always looking into the camera, even when you’re not. It was designed to allow content creators to maintain eye contact while reading from notes or a script, but has been described as creepy and having an uncanny valley effect.

Brazilian broadcaster and Bitmovin partner Globo is using AI to create new revenue streams for their version of the Big Brother reality TV show. At the 2023 NAB Streaming Summit, Mauricio Felix, Director of Technology and Infrastructure for Grupo Globo shared how they are using computer vision and video recognition to create a new “follow the leader” feed that tracks the Head of Household wherever they go, automatically switching between over 60 installed cameras. Similar technology is running behind the scenes of advanced video surveillance and security applications.
Also at this year’s NAB Show, Adobe debuted AI-powered text-based video editing in their Premiere Pro software that they say will make video editing as easy as copying and pasting text. Powered by Adobe Sensei, clips are analyzed and transcribed, allowing anyone to grab text and have the corresponding clip appear on the timeline. Premiere Pro also added a few other AI-powered features to automate tasks like color matching clips, object removal, and reframing to different aspect ratios.
Standards groups have also been seriously considering the applications of AI for video. MPEG has opened explorations into Video Coding for Machines and Neural Network-based Video Compression, both of which have moved into the working draft phase. After finalizing the VVC standard, the Joint Video Experts Team (JVET) began investigating new technologies for the next generation of codecs, one of which is Neural Network based Video Coding (NNVC). There’s also a relatively recently established organization, MPAI – Moving Picture, Audio and Data Coding by Artificial Intelligence, that was created to develop standards for AI-based coding and licensing.
Bitmovin and ATHENA AI Research
For a few years before this recent wave of interest, Bitmovin and our ATHENA project colleagues have been researching the practical applications of AI for video streaming services. It’s something we’re exploring from several angles, from boosting visual quality and upscaling older content to more intelligent video processing for adaptive bitrate (ABR) switching. It might not have the viral appeal of Will Smith eating spaghetti, but the results of this research can make every streaming experience better, which is a lot more exciting (and less gross)! Keep reading to learn more about some of the highlights of our recently published AI video research and how they can enhance future viewing experiences. I’ll give a short summary of each project and link to details for anyone interested in learning more.
Better quality with neural network-driven Super Resolution upscaling
The first group of ATHENA publications we’re looking at all involve the use of neural networks to drive visual quality improvements using Super Resolution upscaling techniques.
DeepStream: Video streaming enhancements using compressed deep neural networks
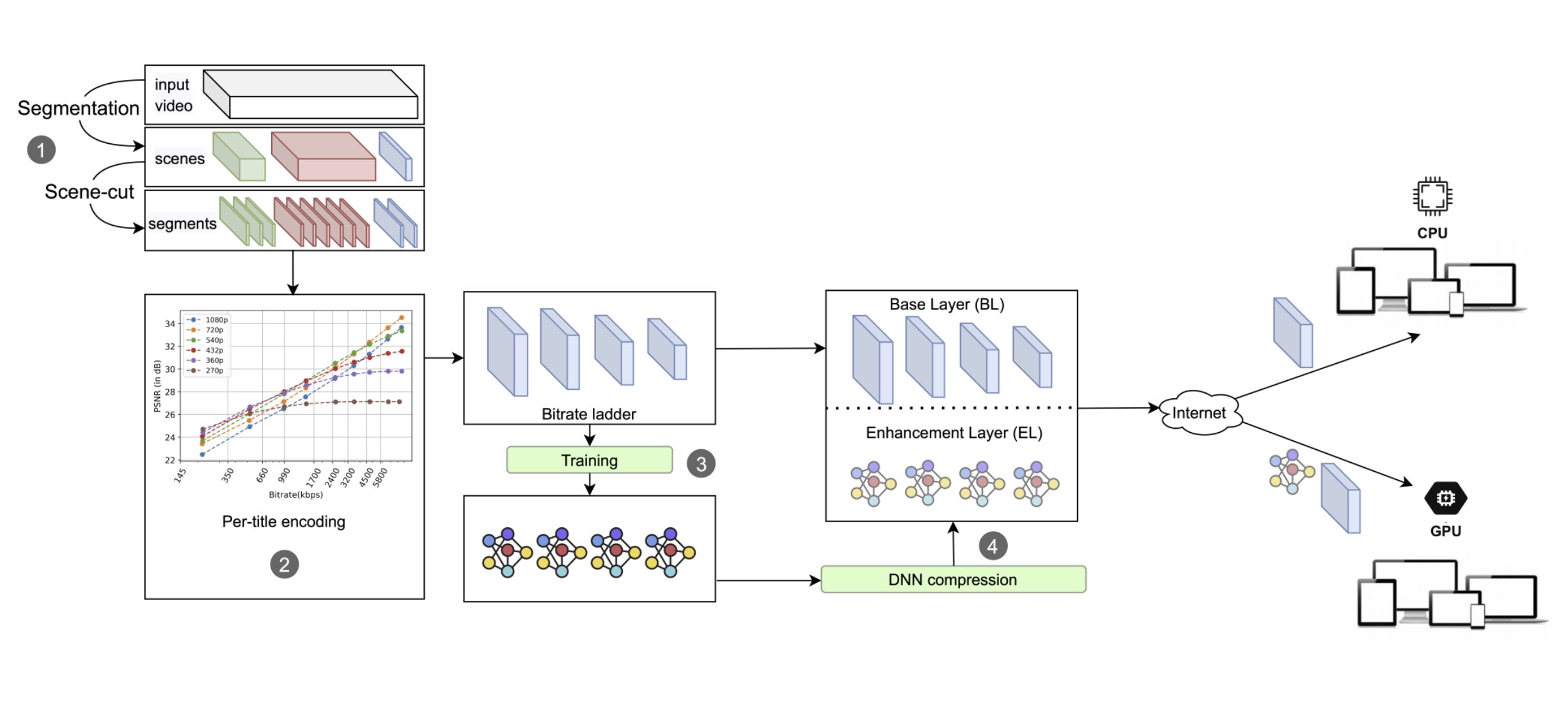
Deep learning-based approaches keep getting better at enhancing and compressing video, but the quality of experience (QoE) improvements they offer are usually only available to devices with GPUs. This paper introduces DeepStream, a scalable, content-aware per-title encoding approach to support both CPU-only and GPU-available end-users. To support backward compatibility, DeepStream constructs a bitrate ladder based on any existing per-title encoding approach, with an enhancement layer for GPU-available devices. The added layer contains lightweight video super-resolution deep neural networks (DNNs) for each bitrate-resolution pair of the bitrate ladder. For GPU-available end-users, this means ~35% bitrate savings while maintaining equivalent PSNR and VMAF quality scores, while CPU-only users receive the video as usual. You can learn more here.
LiDeR: Lightweight video Super Resolution for mobile devices
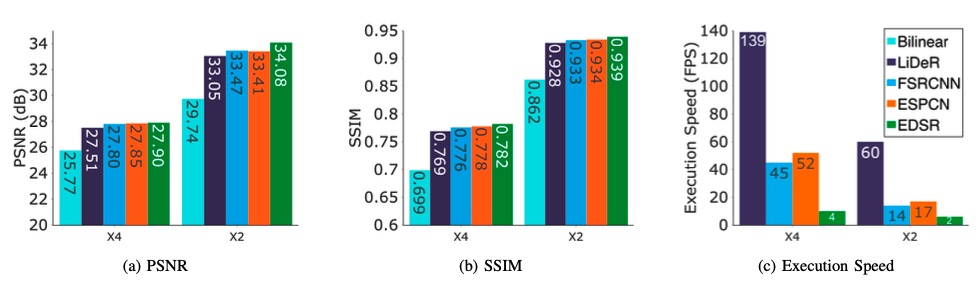
Although DNN-based Super Resolution methods like DeepStream show huge improvements over traditional methods, their computational complexity makes it hard to use them on devices with limited power, like smartphones. Recent improvements in mobile hardware, especially GPUs, made it possible to use DNN-based techniques, but existing DNN-based Super Resolution solutions are still too complex. This paper proposes LiDeR, a lightweight video Super Resolution network specifically tailored toward mobile devices. Experimental results show that LiDeR can achieve competitive Super Resolution performance with state-of-the-art networks while improving the execution speed significantly. You can learn more here or watch the video presentation from an IEEE workshop.
Super Resolution-based ABR for mobile devices
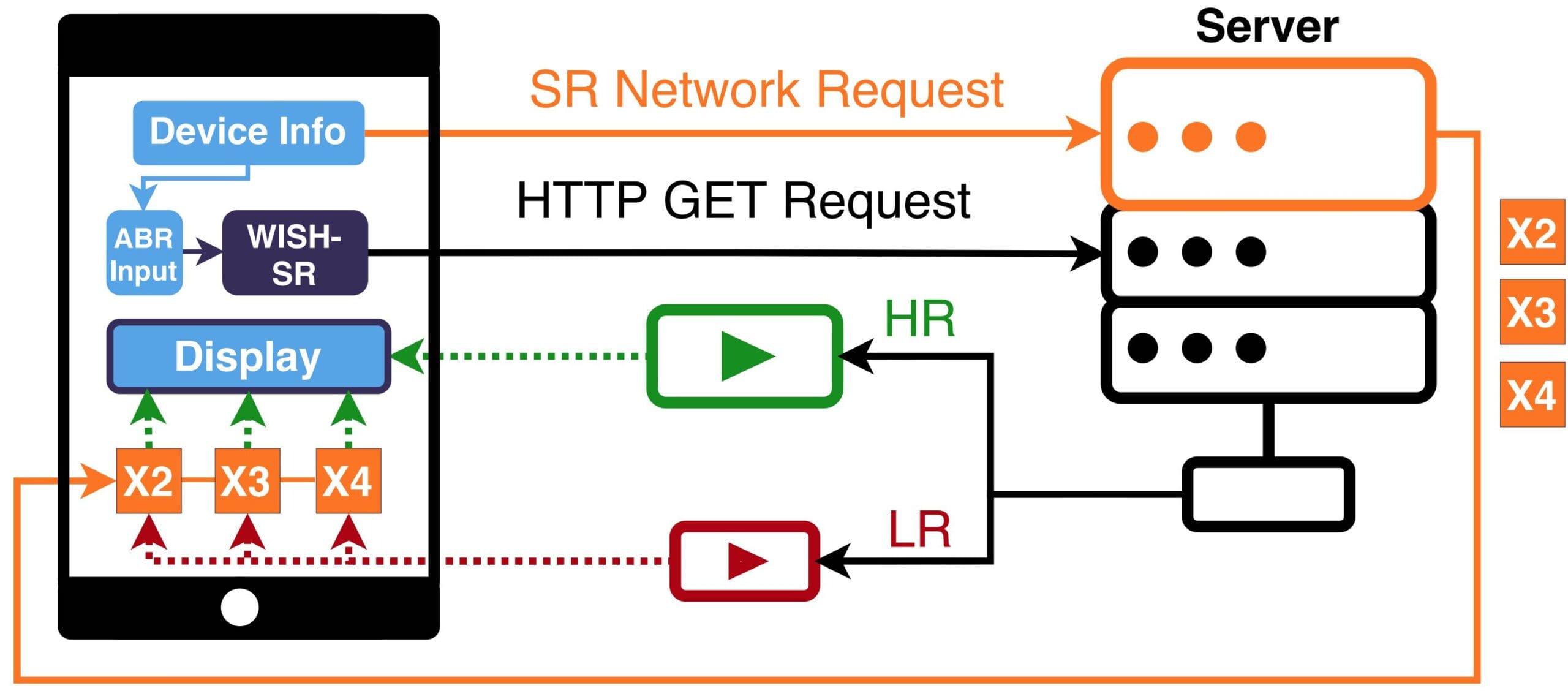
This paper introduces another new lightweight Super Resolution network, SR-ABR Net, that can be deployed on mobile devices to upgrade low-resolution/low-quality videos while running in real-time. It also introduces a novel ABR algorithm, WISH-SR, that leverages Super Resolution networks at the client to improve the video quality depending on the client’s context. By taking into account device properties, video characteristics, and user preferences, it can significantly boost the visual quality of the delivered content while reducing both bandwidth consumption and the number of stalling events. You can learn more here or watch the video presentation from Mile High Video.
Less buffering and higher QoE with applied machine learning
The next group of research papers involve applying machine learning at different stages of the video workflow to improve QoE for the end user.
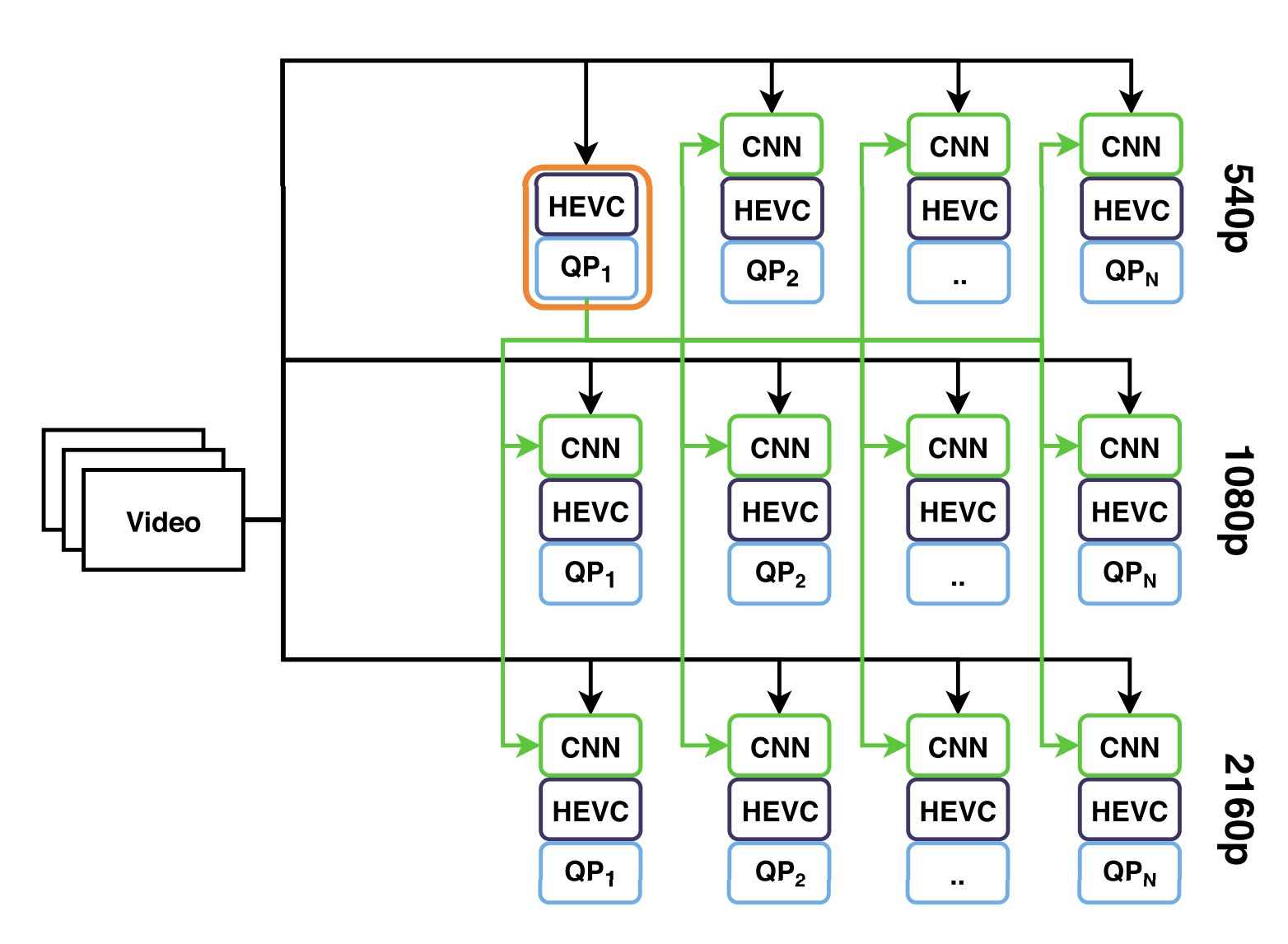
FaRes-ML: Fast multi-resolution, multi-rate encoding
Fast multi-rate encoding approaches aim to address the challenge of encoding multiple representations from a single video by re-using information from already encoded representations. In this paper, a convolutional neural network is used to speed up both multi-rate and multi-resolution encoding for ABR streaming. Experimental results show that the proposed method for multi-rate encoding can reduce the overall encoding time by 15.08% and parallel encoding time by 41.26%. Simultaneously, the proposed method for multi-resolution encoding can reduce the encoding time by 46.27% for the overall encoding and 27.71% for the parallel encoding on average. You can learn more here.
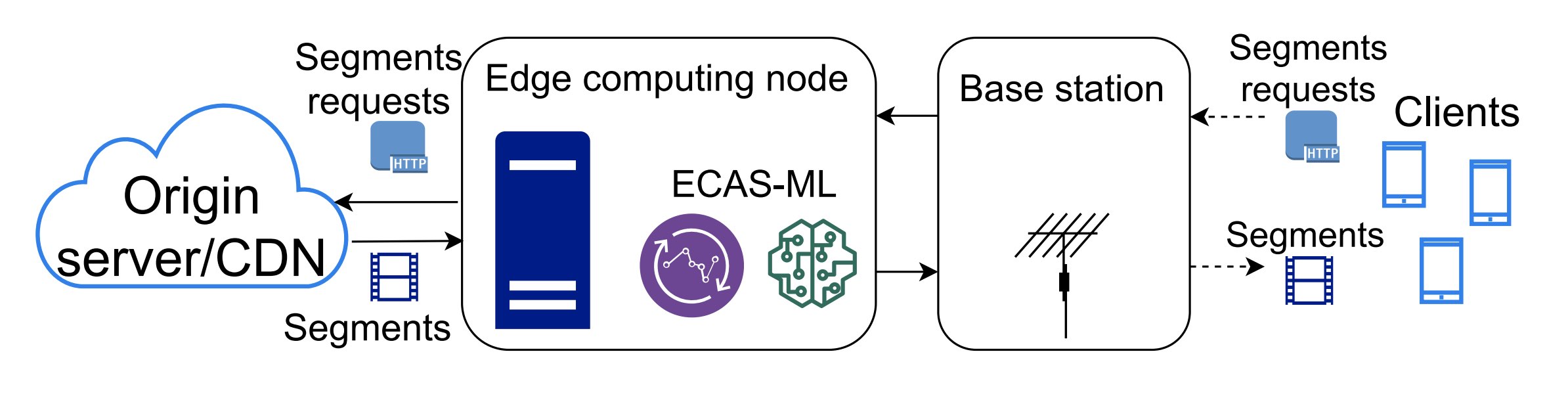
ECAS-ML: Edge assisted adaptive bitrate switching
As video streaming traffic in mobile networks increases, utilizing edge computing support is a key way to improve the content delivery process. At an edge node, we can deploy ABR algorithms with a better understanding of network behavior and access to radio and player metrics. This project introduces ECAS-ML, Edge Assisted Adaptation Scheme for HTTP Adaptive Streaming with Machine Learning. It uses machine learning techniques to analyze radio throughput traces and balance the tradeoffs between bitrate, segment switches and stalls to deliver a higher QoE, outperforming other client-based and edge-based ABR algorithms. You can learn more here.
Challenges ahead
The road from research to practical implementation is not always quick or direct or even possible in some cases, but fortunately that’s an area where Bitmovin and ATHENA have been working together closely for several years now. Going back to our initial implementation of HEVC encoding in the cloud, we’ve had success using small trials and experiments with Bitmovin’s clients and partners to provide real-world feedback for the ATHENA team, informing the next round of research and experimentation toward creating viable, game-changing solutions. This innovation-to-product cycle is already in progress for the research mentioned above, with promising early quality and efficiency improvements.
Many of the advancements we’re seeing in AI are the result of aggregating lots and lots of processing power, which in turn means lots of energy use. Even with processors becoming more energy efficient, the sheer volume involved in large-scale AI applications means energy consumption can be a concern, especially with increasing focus on sustainability and energy efficiency. From that perspective, for some use cases (like Super Resolution) it will be worth considering the tradeoffs between doing server-side upscaling during the encoding process and client-side upscaling, where every viewing device will consume more power.
Learn more
Want to learn more about Bitmovin’s research and development? Check out the links below.
Super Resolution with Machine Learning webinar
AI Video Glossary
Machine Learning – Machine learning is a subfield of artificial intelligence that deals with developing algorithms and models capable of learning and making predictions or decisions based on data. It involves training these algorithms on large datasets to recognize patterns and extract valuable insights. Machine learning has diverse applications, such as image and speech recognition, natural language processing, and predictive analytics.
Neural Networks – Neural networks are sophisticated algorithms designed to replicate the behavior of the human brain. They are composed of layers of artificial neurons that analyze and process data. In the context of video streaming, neural networks can be leveraged to optimize video quality, enhance compression techniques, and improve video annotation and content recommendation systems, resulting in a more immersive and personalized streaming experience for users.
Super Resolution – Super Resolution upscaling is an advanced technique used to enhance the quality and resolution of images or videos. It involves using complex algorithms and computations to analyze the available data and generate additional details. By doing this, the image or video appears sharper, clearer, and more detailed, creating a better viewing experience, especially on 4K and larger displays.
Graphics Processing Unit (GPU) – A GPU is a specialized hardware component that focuses on handling and accelerating graphics-related computations. Unlike the central processing unit (CPU), which handles general-purpose tasks, the GPU is specifically designed for parallel processing and rendering complex graphics, such as images and videos. GPUs are widely used in various industries, including gaming, visual effects, scientific research, and artificial intelligence, due to their immense computational power.
Video Understanding – Video understanding is the ability to analyze and comprehend the information present in a video. It involves breaking down the visual content, movements, and actions within the video to make sense of what is happening.